
Apache Spark is one of the most prominent unified analytics frameworks designed for Big Data Processing. It also has built-in modules for performing various tasks like graph processing, streaming, machine learning, large-scale SQL, stream processing, batch processing, etc. Spark provides high-level APIs in different programming languages like R, Java, Python, Scala, and a lot more. Apache Spark can also distribute large-scale data processing tasks across multiple computers using distributed computing tools or on its own.
The below image provides you a nutshell of Spark Architecture.

Spark is the most popular data processing framework. It follows master-slave architecture. The Apache Spark cluster consists of multiple slaves and a single master. The Spark architecture depends on two abstractions such as Directed Acyclic Graph (DAG) and Resilient Distributed Dataset (RDD). Spark Applications run as an independent set of processes on clusters. The key role of RDD is to restore the data on failure and then distribute it among different nodes. After it, the data is grouped in the datasets. Directed Acyclic Graph is mainly used to perform data computation. From the above image, you will get a detailed understanding of the process flow in Apache Spark Architecture.
Spark is the most popular platform used by many organizations and vendors for large-scale data processing.

The key components of Spark are as follows:
- Spark SQL
- Spark Streaming
- MLlib
- GraphX
- Spark Core
Spark SQL is the most prominent Spark module designed for structured data processing. Spark SQL interfaces provide more information for the Spark about the structure of computation and data. To perform extra optimizations Spark SQL uses this extra information. The key use of Spark SQL is to execute SQL queries and also used to read data from the existing Hive installation. Spark SQL supports both ODBC and JDBC connections. Moreover, it also supports various sources of data like JSON, Parquet, and Hive Tables.

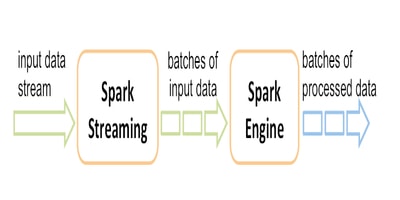
Spark Streaming is the essential component of Apache Spark. This component is also considered as an extension of the Spark API. The main function of Spark Streaming is to enable fault-tolerant, high-throughput, and scalable processing of data streams. Spark streaming also helps you in representing a continuous stream of data using Spark High-level abstraction called DStream. It also lets you reuse the same code for batch processing.
There are two main libraries present in Apache Spark and they are MLlib and GraphX. The MLlib is the scalable and most prominent machine learning library of Spark. This library consists of various learning algorithms and utilities such as collaborative filtering, regression, classification, dimensionality reduction, clustering, and many more. Furthermore, it also contains underlying optimization primitives like statistics, transformation, extraction, data types, etc.
The GraphX library in Apache Spark is used to perform graph-parallel computations and manipulate graphs. It consists of the growing collection of graph algorithms. Spark RDD is extended by GraphX with Resilient Distributed Property Graph.
The comparison between Apache Spark and Hadoop is as follows:
Apache Spark | Hadoop |
Apache Spark is one of the most prominent unified analytics frameworks designed for Big Data Processing. | Apache Hadoop is the popular open-source platform. It is a collection of software utilities. It also provides a software framework for the processing of big data and for storage distribution. |
Apache Spark is written in Java Programming and Scala programming | Apache Hadoop is written and developed in Java Programming |
It is compact and it is easier compare to Hadoop | Lengthy and complex |
Apache Spark speed is 100x times faster than MapReduce | It is faster than the traditional system |
It is Open Source | It is open source |
It involves real-time processing, batch processing, graph processing, etc. | It involves batch processing |
Apache Spark is a popular unified analytics framework used for processing large-scale data workloads. It uses an in-memory caching mechanism for faster queries. Spark framework is also used for creating data pipelines, run distributed SQL, rum machine learning algorithms, a lot more.
Spark Framework is a free and open-source web application platform designed for Big Data Processing. Apache Spark can also distribute large-scale data processing tasks across multiple computers using distributed computing tools or on its own. Spark provides an alternative for developers who want to develop web applications. It is the rapid and fastest development framework for processing big data.
Spark context Parallelize method is mainly used to create a personalized collection. This Spark parallelism allows Apache Spark to distribute the data among different nodes to avoid depending on a single node to process the data. The Spark context parallelize method is represented in the following manner sc.parallelize(). In Spark, when the task is parallelized means that the concurrent tasks are running on the worker nodes.